

Iako živimo u vremenu izvanredne inovacije u mašinskom učenju ubrzanom GPU-om, najnovija istraživačka dokumenta često (i izraženo) sadrže algoritme koji su decenijama, u nekim slučajevima čak 70 godina stari.
Neki bi mogli tvrditi da mnoge od ovih starijih metoda pripadaju „statističkoj analizi“ umesto mašinskom učenju, i radije bi datirali početak sektora samo do 1957. godine, sa izumom Perceptrona.
S obzirom na to koliko ovi stariji algoritmi podržavaju i uklapaju se u najnovije trendove i vodeće razvoje u mašinskom učenju, to je diskutabilan stav. Zato pogledajmo neke od „klasičnih“ građevnih blokova koji leže u osnovi najnovijih inovacija, kao i neke nove ulaze koji već prave ranu prijavu za AI Kuću slavnih.
1: Transformeri
Godine 2017. istraživački tim Google Research predvodio je saradnju koja je rezultirala radom pod nazivom „Pažnja je sve što vam je potrebno“ (Attention Is All You Need). Rad je predstavio novu arhitekturu koja je promovisala mehanizme pažnje iz „prosleđivanja“ u enkoder/dekoder i rekurentnim mrežama u centralnu transformacionu tehnologiju samu po sebi.
Pristup je nazvan Transformer, i postao je revolucionarna metodologija u obradi prirodnog jezika (Natural Language Processing – NLP), koja pokreće, između ostalog, autoregresivni model jezika i AI uzorak GPT-3
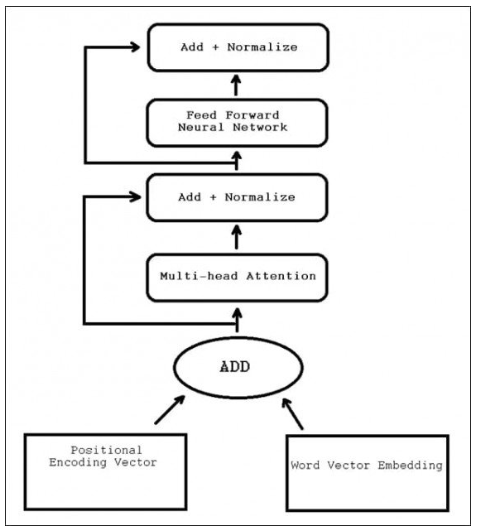
Transformeri su elegantno rešili problem sekvenčne transdukcije, takođe nazvan „transformacija“, koji se bavi obradom ulaznih sekvenci u izlazne sekvence. Transformator takođe prima i obrađuje podatke na kontinuiran način, umesto u sekvencijalnim serijama, omogućavajući „trajnost memorije“ koju RNN arhitekture nisu dizajnirane da postignu. Za detaljniji pregled transformera, pogledajte naš referentni članak.
Za razliku od rekurentnih neuronskih mreža (RNN) koje su počele dominirati u istraživanjima mašinskog učenja u doba CUDA-e, arhitektura transformera takođe se može lako paralelizovati, otvarajući put za produktivno rukovanje mnogo većim korpusom podataka od RNN-ova.
Popularna upotreba
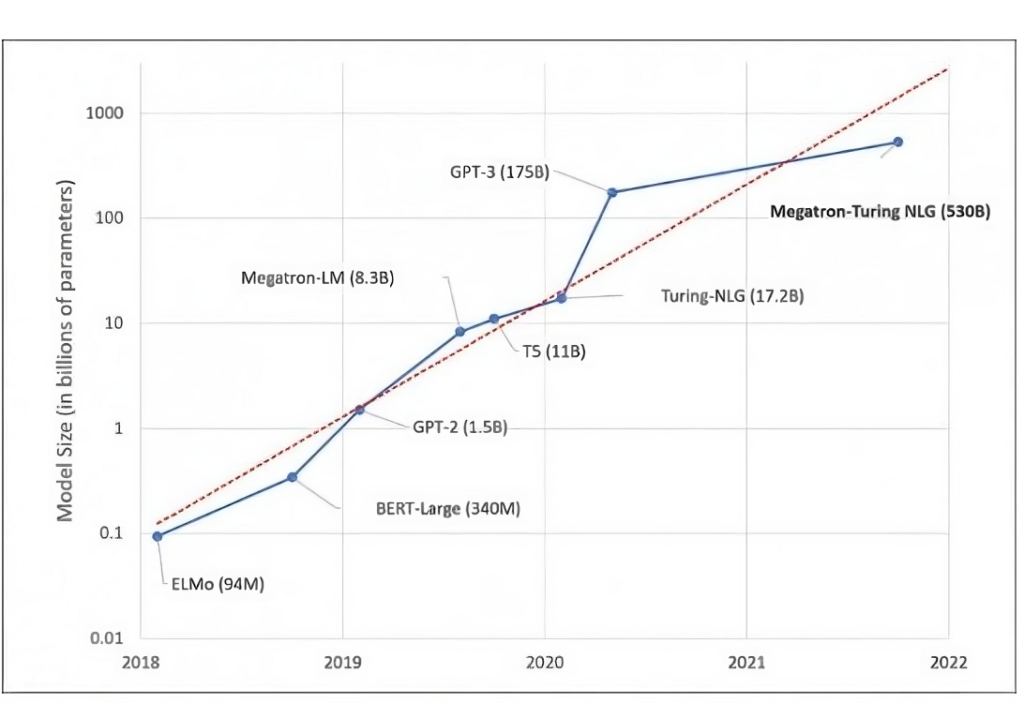
Transformeri su privukli pažnju javnosti 2020. godine izdanjem GPT-3 od strane OpenAI-a, koji se ponosio tada rekordnih 175 milijardi parametara. Ovo navodno izvanredno postignuće kasnije je zasenjeno kasnijim projektima, poput izdanja Megatron-Turing NLG 530B od strane Microsofta 2021. godine, koji (kao što naziv sugeriše) sadrži preko 530 milijardi parametara.
Arhitektura transformera takođe je prešla iz oblasti obrade prirodnog jezika (NLP) na računalnu viziju, pokrećući novu generaciju okvira za sintezu slika kao što su CLIP i DALL-E koje je razvio OpenAI. Ovi okviri koriste mapiranje iz teksta u sliku kako bi dovršili nepotpune slike i sintetizirali nove slike iz obučenih domena, među rastućim brojem srodnih primena.
2. Generativne antagonističke mreže (GAN-ovi)
Izvorno predložene 2014. godine i uglavnom korišćene za sintezu slika, arhitektura Generativnih antagonističkih mreža (GAN) sastoji se od Generatora i Diskriminatora. Generator prolazi kroz hiljade slika u skupu podataka i iterativno pokušava da ih rekonstruiše. Za svaki pokušaj, Diskriminator ocenjuje rad Generatora i vraća ga da radi bolje, ali bez ikakvog uvida u način na koji je prethodna rekonstrukcija pogrešila.
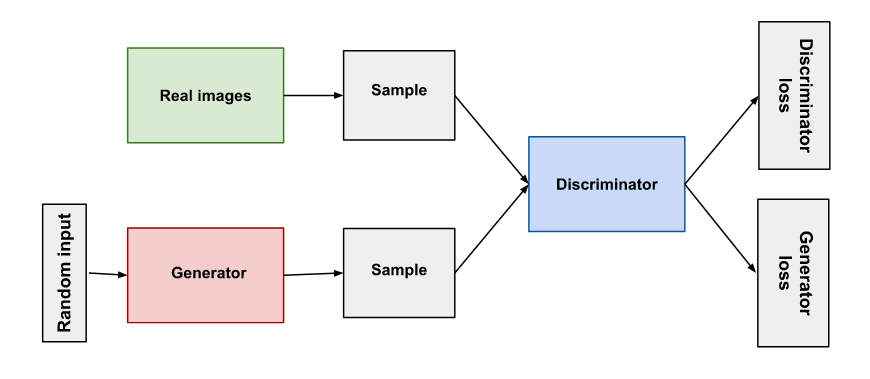
Ovo prisiljava Generator da istražuje različite pravce umesto da sledi potencijalne ćorsokake koje bi rezultirale da mu Diskriminator kaže gde greši (vidi #8 u nastavku). Do kraja treninga, Generator ima detaljnu i sveobuhvatnu mapu odnosa između tačaka u skupu podataka.
Po analogiji, to je kao razlika između učenja jedne obične vožnje do centralnog Londona ili pažljivog sticanja The Knowledge(znanja).
Rezultat je visok nivo skupljanja karakteristika u latentnom prostoru obučenog modela. Semantički indikator za karakteristiku visokog nivoa može biti „osoba“, dok bi silazak kroz specifičnost povezanu sa karakteristikom mogao otkriti druge naučene osobine kao što su „muško“ i „žensko“. Na nižim nivoima, pod-karakteristike mogu se raslojavati na „plavokose“, „kavkaska“ itd.
Zapetljavanje (entanglement) je primetan problem u latentnom prostoru GAN-ova i okvira enkoder/dekoder: da li je osmeh na ženskom licu generisanom od strane GAN-a zapetljana karakteristika njenog „identiteta“ u latentnom prostoru ili je to paralelna grana?
Poslednjih nekoliko godina donelo je sve više novih istraživačkih inicijativa u vezi s tim, što možda otvara put za uređivanje latentnog prostora GAN-a na nivou karakteristika, slično kao što se to radi u Photoshopu. Međutim, trenutno mnoge transformacije su efektivno „sve ili ništa“ paketi. Treba napomenuti da je NVIDIA-ino izdanje EditGAN koje je objavljeno krajem 2021. postiglo visok stepen interpretabilnosti u latentnom prostoru koristeći semantičke segmentacione maske.
Popularna Upotreba
Pored njihove (zapavo prilično ograničene) uključenosti u popularne deepfake video snimke, GAN-ovi usmereni na slike i video sadržaje su se proširili u poslednjih četiri godine i očarali kako istraživače tako i javnost. Održavanje korak sa brzim i čestim novim izdanjima je izazov, iako GitHub repozitorijum „Awesome GAN Applications“ ima za cilj da pruži sveobuhvatnu listu.
Generative Adversarial Networks teorijski mogu izvoditi karakteristike iz bilo kog dobro definisanog domena, uključujući tekst.
3. SVM (Support Vector Machine)
SVM (Support Vector Machine) je osnovni algoritam za mašinsko učenje koji se često javlja u novim istraživanjima, a potiče iz 1963. godine. U okviru SVM-a, vektori mapiraju relativni raspored tačaka podataka u skupu podataka, dok podržavajući vektori određuju granice između različitih grupa, karakteristika ili osobina.
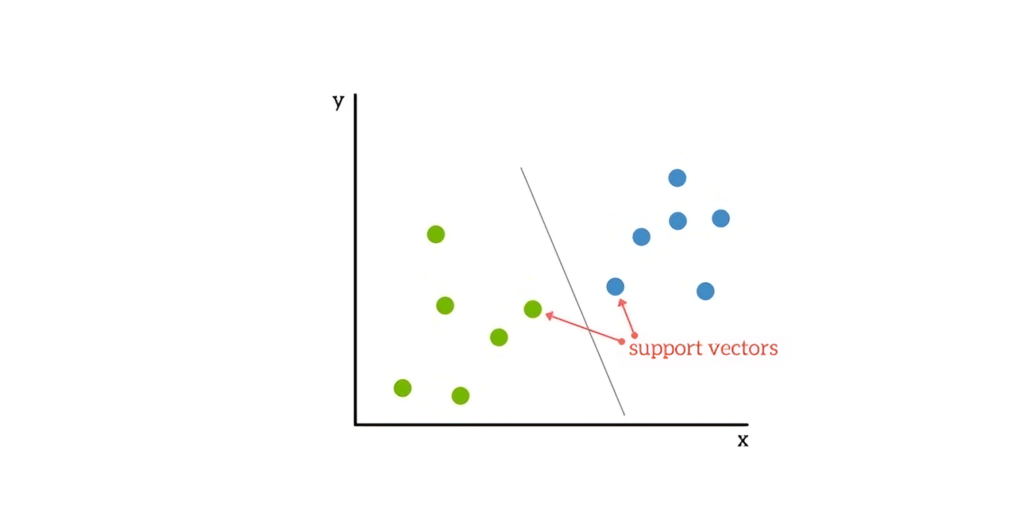
Granica koju dobijamo korišćenjem SVM algoritma naziva se hiper-ravan. Na niskim nivoima karakteristika, SVM je dvodimenzionalan (kao na slici iznad), ali kada imamo veći broj prepoznatih grupa ili tipova, postaje trodimenzionalan.
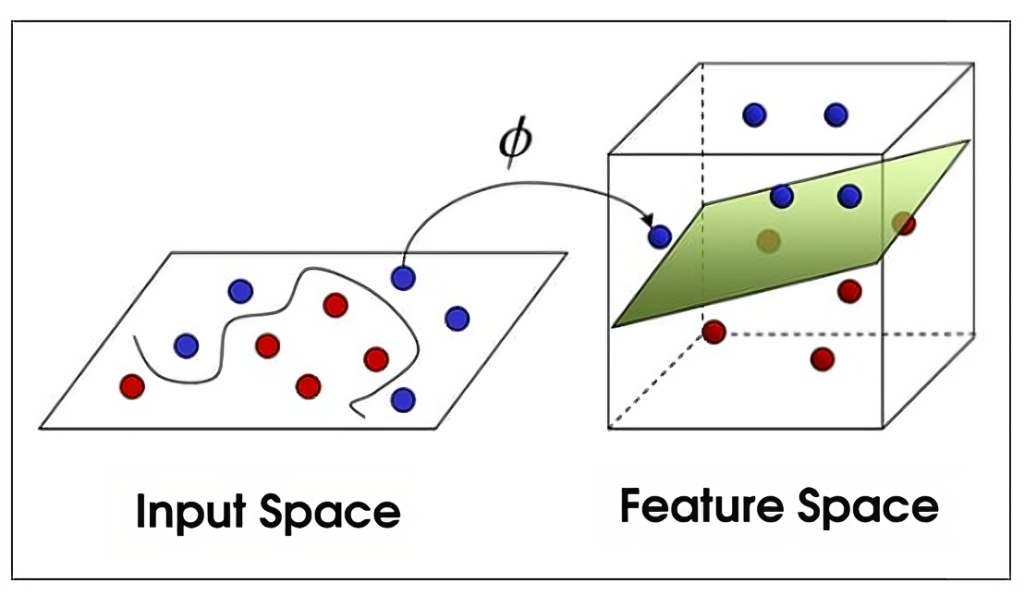
Popularna upotreba
Pošto Support Vector Machine (SVM) može efikasno i agnostično rešavati visokodimenzionalne podatke različitih vrsta, on se široko koristi u različitim sektorima mašinskog učenja, uključujući detekciju deepfake-a, klasifikaciju slika, klasifikaciju govora mržnje, analizu DNK i predviđanje populacijske strukture, među mnogim drugim primenama.
4. K-Means Klasterovanje
Klasterovanje (clustering) uopšteno je pristup nenadgledanom učenju koji pokušava kategorizirati tačke podataka kroz procenu gustine, stvarajući mapu distribucije proučavanih podataka.

K-Means algoritam za mašinsko učenje postao je najpopularnija implementacija ovog pristupa, grupišući tačke podataka u različite „K grupe“, koje mogu ukazivati na demografske sektore, online zajednice ili bilo koju drugu moguću skrivenu agregaciju koja čeka da bude otkrivena u sirovim statističkim podacima.

Vrednost K sama po sebi je faktor koji određuje korisnost procesa i utvrđivanje optimalne vrednosti za klaster. Početno, vrednost K se nasumično dodeljuje, a zatim se porede njene karakteristike i vektorske osobine sa svojim susedima. Susedi koji najviše liče na podatke sa nasumično dodeljenom vrednošću se iterativno dodeljuju njenom klasteru sve dok podaci ne otkriju sve grupe koje proces dozvoljava.
Grafik za kvadratnu grešku, ili ‘cost’ različitih vrednosti između klastera će otkriti tačku lakta za podatke:

Tačka lakta je slična konceptu načinu na koji gubitak (loss) dostiže zasićenje i opada do smanjenih povrata na kraju trening sesije za skup podataka. Predstavlja tačku u kojoj dalje razlike između grupa neće postati očigledne, što ukazuje na trenutak za prelazak na sledeće faze u obradi podataka ili izveštavanje o rezultatima.
Popularna upotreba
K-Means klasterovanje, iz očiglednih razloga, predstavlja osnovnu tehnologiju u analizi korisnika, jer nudi jasnu i objašnjivu metodologiju za pretvaranje velikih količina komercijalnih podataka u demografske uvide i „leads“.
Van ove primene, K-Means klasterovanje se takođe koristi za predviđanje klizišta, segmentaciju medicinskih slika, sintezu slika pomoću GAN-a, klasifikaciju dokumenata i urbanističko planiranje, među mnogim drugim mogućim i stvarnim primenama.
5. Random Forest
Random Forest je algoritam za mašinsko učenje koji izračunava prosečan rezultat iz niza stabala odlučivanja.
Ako ste se malo upoznali s ovom metodom, možete je zamisliti kao drvo odlučivanja: ispred vas se nalazi nekoliko puteva, a svaki put se razgranava ka novom rezultatu koji dalje sadrži moguće nove puteve.
U kontekstu pojačanog učenja, možete se vratiti sa jednog puta i početi iznova, dok stabla odlučivanja ostaju posvećena svojim putovanjima.
Stoga je algoritam Random Forest suštinski metod širenja oklade za odluke. Algoritam se naziva „random“ zato što pravi ad hoc selekcije i posmatranja kako bi razumeo srednju sumu rezultata iz niza stabala odlučivanja.
S obzirom da uzima u obzir više faktora, pristup Random Forest-a može biti teže pretvoriti u značajne grafikone u odnosu na stabla odlučivanja, ali je verovatno znatno produktivniji.
Stabla odlučivanja su podložna preprilagođavanju, gde se dobijeni rezultati odnose na specifične podatke i nisu verovatni za generalizaciju. Nasumičan izbor tačaka podataka od strane Random Forest-a se bori protiv ove tendencije, pronalazeći značajne i korisne trendove u podacima.

Popularna primena
Kao i mnogi algoritmi na ovom spisku, Random Forest se obično koristi kao „rani“ sortirac i filter podataka, i kao takav se redovno pojavljuje u novim istraživačkim radovima. Neki primeri upotrebe Random Forest-a uključuju sintezu magnetske rezonance slika, predviđanje cene bitkoina, segmentaciju popisa stanovništva, klasifikaciju teksta i otkrivanje prevara sa kreditnim karticama.
Budući da je Random Forest niskonivojski algoritam za mašinsko učenje, može doprineti performansama drugih niskonivojskih metoda, kao i vizualizacijskim algoritmima, uključujući induktivno klasterovanje, transformacije karakteristika, klasifikaciju tekstualnih dokumenata koristeći široke karakteristike i prikazivanje Pipelines.
6. Naive Bayes
Uparivan s procenom gustine (vidi 4, iznad), Naive Bayes klasifikator je moćan, ali relativno lak algoritam za mašinsko učenje koji može procenjivati verovatnoće na osnovu izračunatih karakteristika podataka.
Izraz „naivni“ odnosi se na pretpostavku u Bajesovoj teoremi da su karakteristike nezavisne, poznate kao uslovna nezavisnost. Ako prihvatimo ovu tačku gledišta, hodanje i pričanje kao patka nisu dovoljni da bi se utvrdilo da imamo posla sa patkom, i nema „očiglednih“ pretpostavki koje su usvojene unapred.

Ovaj nivo akademske i istraživačke rigoroznosti bio bi preteran tamo gde je „zdrav razum“ dostupan, ali je vredan standard kada se prelazi preko mnogih nejasnoća i potencijalno nezavisnih korelacija koje mogu postojati u skupu podataka za mašinsko učenje.
U originalnoj Bajesovoj mreži, karakteristike su podložne funkcijama ocenjivanja, uključujući minimalnu dužinu opisa i Bajesovo ocenjivanje, koja mogu nametnuti ograničenja podacima u smislu procenjenih veza između tačaka podataka i smera u kojem te veze teku.
Nasuprot tome, naivni Bayes klasifikator radi na pretpostavci da su karakteristike datog objekta nezavisne, i zatim koristi Bajesovu teoremu za izračunavanje verovatnoće datog objekta na osnovu njegovih karakteristika.
Popularna primena
Naivni Bayes filteri su dobro zastupljeni u predviđanju bolesti i kategorizaciji dokumenata, filtriranju spama, klasifikaciji sentimenta, sistemima preporuka i otkrivanju prevara, među ostalim primenama.
7. K- Nearest Neighbors (KNN)
Prvi put predložen od strane US Air Force School of Aviation Medicine 1951. godine, i suočavajući se sa tadašnjim dostignućima računarske tehnologije sredine 20. veka, K-Nearest Neighbors (KNN) je efikasan algoritam za mašinsko učenje koji i dalje zauzima istaknuto mesto u akademskim radovima i istraživačkim inicijativama za mašinsko učenje u privatnom sektoru.
KNN je nazvan „lenjim učiteljem“ jer iscrpno pretražuje skup podataka radi evaluacije odnosa između tačaka podataka, umesto zahteva za obukom potpunog modela za mašinsko učenje.
Iako je KNN arhitektonski jednostavan, njegov sistematičan pristup zahteva primetne operacije čitanja i pisanja, a njegova upotreba u veoma velikim skupovima podataka može biti problematična bez dodatnih tehnologija poput Principal Component Analysis (PCA), koja može transformisati složene i velike skupove podataka u reprezentativne grupisanja koje KNN može obrađivati sa manjim naporom.
Nedavna studija je procenila efikasnost i ekonomičnost nekoliko algoritama zaduženih za predviđanje da li će zaposleni napustiti kompaniju, pri čemu je otkriveno da je KNN, star sedam decenija, ostao superiorniji u smislu tačnosti i prediktivne efektivnosti u odnosu na modernije konkurente.
Popularna primena
Uprkos svojoj popularnoj jednostavnosti koncepta i primene, KNN nije zaglavljen u pedesetim godinama – prilagođen je u pristupu usmerenom na duboko neuronsko učenje (DNN) u predlogu iz 2018. godine sa Pennsylvanijskog univerziteta i i dalje je centralni proces u mnogim složenijim okvirima za mašinsko učenje, kao početna faza ili alat za postprocesiranje analize.
U različitim konfiguracijama, KNN se koristi za online verifikaciju potpisa, klasifikaciju slika, rudarenje teksta, predviđanje useva i prepoznavanje lica, kao i druge primene i uključivanja.
8. Markov Decision Process (MDP)
Matematički okvir koji je predstavio američki matematičar Richard Bellman 1957. godine, Markovljev proces odlučivanja (Markov Decision Process – MDP) je jedan od najosnovnijih elemenata arhitekture za učenje pojačavanja. Kao konceptualni algoritam sam za sebe, prilagođen je u mnoge druge algoritme i često se pojavljuje u trenutnom nizu istraživanja veštačke inteligencije i mašinskog učenja.
MDP istražuje okruženje podataka koristeći evaluaciju trenutnog stanja (tj. „gde“ se nalazi u podacima) kako bi odlučio koji čvor podataka istražiti sledećeg.
Osnovni Markovljev proces odlučivanja prioritet daje bliskim prednostima u odnosu na željene dugoročne ciljeve. Iz tog razloga se obično ugrađuje u kontekst sveobuhvatne politike arhitekture za učenje pojačanja i često je podložan ograničavajućim faktorima poput diskontovane nagrade i drugih modifikacija okruženja koje sprečavaju naglo dostizanje trenutnog cilja bez razmatranja šireg željenog ishoda.
Popularna primena
Koncept MDP-a je široko rasprostranjen i u istraživanjima i u aktivnim primenama mašinskog učenja. Predložen je za sisteme za odbranu IoT sigurnosti, ribolov i prognoziranje tržišta.
Pored očigledne primene u šahu i drugim striktno sekvencijalnim igrama, MDP je takođe prirodan kandidat za proceduralno obučavanje robotskih sistema, kao što možemo videti u videu ispod.
9: Term Frekvencija-Inverzna frekvencija dokumenta
Term Frekvencija (TF) deli broj puta kada se određena reč pojavljuje u dokumentu sa ukupnim brojem reči u tom dokumentu. Na primer, reč „seal“ koja se pojavi jednom u hiljadu reči članka ima term frekvenciju od 0.001. Samo po sebi, TF je uglavnom beskoristan kao indikator važnosti termina, zbog činjenice da prevladavaju besmisleni članci (kao što su „a“, „and“, „the“ i „it“).
Da bismo dobili smislenu vrednost za termin, Inverzna Frekvencija Dokumenta (IDF) računa TF reči u više dokumenata u skupu podataka, dodeljujući nisku ocenu veoma visokofrekventnim zaustavnim rečima, kao što su članci. Rezultirajući vektori karakteristika se normalizuju na celobrojne vrednosti, pri čemu se svakoj reči dodeljuje odgovarajuća težina.
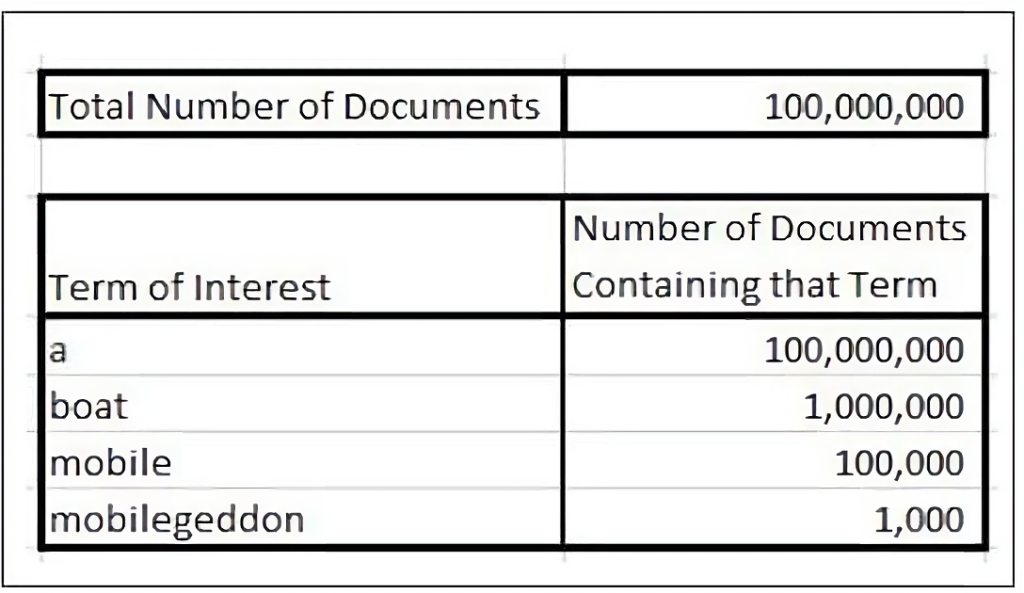
Izuzetno je važno da se napomenuti da inverzno obrnuta frekvencija ne znači automatski da je niskofrekventni termin bezvredan, jer neke stvari su retke i bezvredne. Stoga će niskofrekventni termin morati dokazati svoju vrednost u širem arhitektonskom kontekstu tako što će se pojavljivati (čak i sa niskom frekvencijom po dokumentu) u brojnim dokumentima u skupu podataka.
Uprkos svojoj starosti, TF-IDF je moćna i popularna metoda za početne prolaze filtriranja u okviru obrade prirodnog jezika.
Popularna upotreba
Zbog toga što je TF-IDF bar donekle uticao na razvoj Google-ovog uglavnom tajanstvenog PageRank algoritma tokom poslednjih dvadeset godina, postao je veoma rašireno korišćen kao manipulativna SEO taktika, uprkos izjavi Johna Muellera iz 2019. godine da nije važan za rezultate pretrage.
Zbog tajnovitosti oko PageRanka, ne postoji jasan dokaz da TF-IDF trenutno nije efikasna taktika za poboljšanje rangiranja na Google-u. Nedavne vatrene rasprave među IT stručnjacima ukazuju na popularno razumevanje, ispravno ili ne, da zloupotreba termina i dalje može dovesti do poboljšanja SEO pozicioniranja (iako dodatne optužbe za zloupotrebu monopolne pozicije i prekomernu reklamiranost zamagljuju granice ove teorije).
10. Stohastički gradijentni spust
Stohastički gradijentni spust (SGD) je sve popularnija metoda za optimizaciju treniranja modela mašinskog učenja.
Gradijentni spust sam po sebi predstavlja metod optimizacije i kvantifikaciju poboljšanja koje model postiže tokom treniranja.
U ovom kontekstu, ‘gradijent’ označava nagib naniže (umesto kolorne gradijacije, pogledaj sliku ispod), pri čemu najviša tačka ‘brda’, sa leve strane, predstavlja početak procesa treniranja. U ovoj fazi model još uvek nije video celokupan skup podataka nijednom, i nije dovoljno naučio o odnosima među podacima da bi proizveo efektivne transformacije.


